Today we’re going to learn about Heaps’ Law in linguistics and how it can help us determine if treating musical melodies as made up of “words” like human language is justified. While this topic is necessarily math-oriented and I need to use formulas to be precise, I’ll also add plain language explanations and use figures and charts to aid understanding.
Harold Heaps was a Canadian linguist who lived in the 1900s (he died in 1979) as an educator and researcher. He based his own work on an earlier researcher named George Zipf, an American linguist who was about the same age as Heaps, but died earlier in 1950. Zipf found that linguistics with mathematics were linked by plotting the frequency of a word in a language to find that it was inversely proportional to where it stood in rankings of frequency order. Heaps took that result and refined it, producing the following relationship:
Heaps’ Law: As you start reading the works in any language, the size of the vocabulary of that language at any point is equal to a constant multiplied by the total number of words encountered raised to a power.
That definition is formalized in mathematical language as follows:
where
- V is the vocabulary size
- N is the total number of words encountered altogether, including duplicates
- K is a constant that depends on that langauge
- β is a number that the total number of words is raised to
If that completely throws you, don’t give up. We’ve only included it for completeness.
Here’s an easy-to-understand way to see how this relationship is calculated: Imagine you started reading a book and with each word did the following. If you had not seen that word before in the book, you write it down as a new word and you keep track of all the words you’ve encountered so far. If the first word is “the”, you have one new word and one word total. You then read the second word. If it’s a word different from “the”, you add another tick to each column for a total of two unique words and two words total. Let’s say the first sentence is “The cat in the hat”. After reading that sentence, you would have four in the first column of different words, and five in the column keeping track of total words.
Keep performing this operation, but at every 1,000th word you stop to plot your two numbers on a graph where the number of total words is on the horizontal axis and the number of different (unique) words on the vertical axis. Once you have finished the book, you have the Heaps Chart, a curve showing how vocabulary grows as you read more text. You’ll find that the curve rises quickly at first, then more slowly, but it never completely levels off because new words keep appearing, just less frequently.
As a picture is worth a thousand words, let’s take a look at what a Heaps’ Chart looks like for a book in the public domain. Our example will use Moby Dick by Herman Melville. We wrote a script to create the following Heaps’ Chart for this American classic:
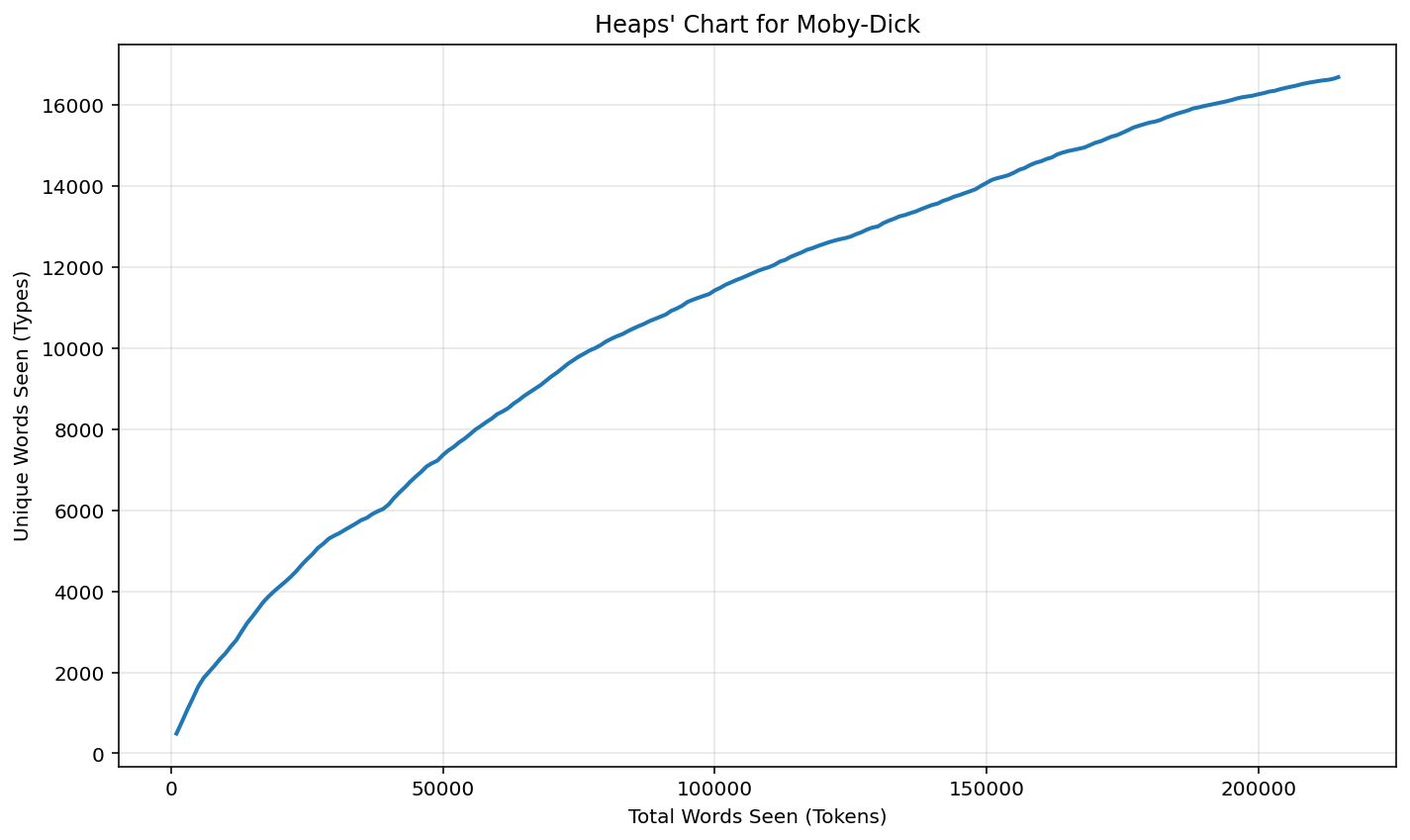
The curve is exactly as we described: It rises quickly and then starts leveling off without ever fully doing so. But a lot of curves fit that description. How do we know the Moby Dick curve follows the very particular form of Heaps’ Law? To answer that question, we fit a Heaps’ Law curve to the Moby Dick data and plot it on top of the raw Moby Dick curve shown above. The result is the following figure:
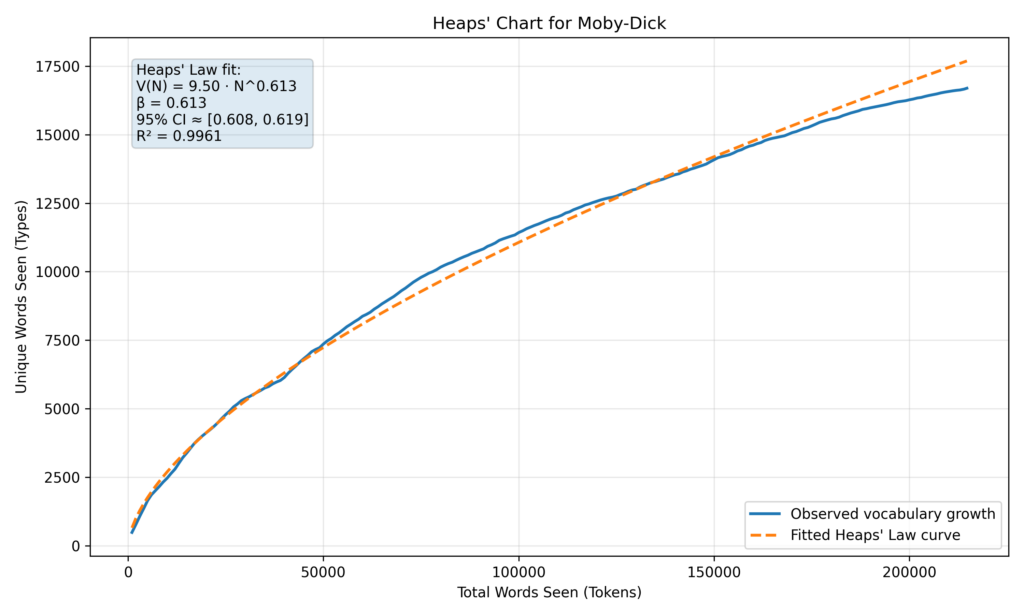
We see a rather close fit to the Moby Dick observed vocabulary curve and the fitted Heaps’ Law curve. We learn from the fitting that the value of beta (β) in the equation for Moby Dick is around 0.6. The upper blue box in the figure tells us more, which is that we have 95 percent confidence the the Moby Dick value for beta is from 0.609 to 0.619, which is a nice, tight range.
The above exercise has been done for countless books, magazines, newspapers, and other forms of printed English. The remarkable thing is that Heaps’ Law holds not only for English, but for other Indo-European languages such as French, Spanish, and German, slavic languages like Russian and Polish, semitic languages such as Arabic and Hebrew, East Asian languages such as Chinese and Japanese, as well as Turkish and Finnish.
However, this is a blog about musical melodies, not languages. In the next post we undertake to find out if the language of music, at least as contained in its melodies, also follows Heaps’ Law. Heaps-like behavior has been observed indirectly in music-related studies, but it has not been cleanly established or standardized.