This week we check to see if music is similar to human language in that it also follows Heaps’ Law. There is not a large body of work on music and Heaps’ Law, at least not compared to that of linguistics. But there is a small, coherent line of research in computational musicology that either tests Heaps’ Law on musical databases (corpora) or establishes Zapf-like scaling in music. The Zipf application is relevant because there’s a mathematical relationship that implies Heaps-like behavior under standard assumptions.
Marc Serra-Peralta, Joan Serra, and Alvaro Corral in 2021 analyzed 9,500 classical works (about 5 million tokens) and found a clear Heaps’ Law scaling with a beta of 0.35. (Heaps’ Law and Vocabulary Richness in the History of Classical Music Harmony). The defined a musical “word” as codewords representing harmonic states (chords and tonal configurations) at each time step. Their analysis is quite different from ours in that it is harmonic, whereas ours is melodic. Still, it’s similar in that a token is an event in sequence and they used pitches and durations (MIDI values, as we did) to represent them. Let’s put a pin in their beta of 0.35.
Byeongchan Choi et al., quite recently (2026), tested different definitions of “musical units” in the paper “Zipf-Mandelbrot Scaling in Korean Court Music”. Their corpus is quite small, just 43 Korean court music pieces spanning about six centuries, for just a total of 65,817 “words”, defined as we are experimenting with: a pitch and a duration. They found a beta (imputed) of 0.36. That’s remarkably close to the Marc Serra-Peralta finding. A side note is that this paper found that pitch or durations alone is too impoverished and didn’t perform well in the Zipf or Heaps analysis. Neither alone is sufficient as a “word”.
In 2025 Manuel Moussallam and Marc Barthelemy studied Heaps and Zipf relationships across various domains including music listening sequences. They show that Heaps-like growth depends on both frequency distribution and temporal structure. This finding is relevant because they suggest that the order in which you feed music to a Heaps’ analysis may change the results (beta). It suggests that we should double check by shuffling the database to randomize the order and see if it affects the robustness of the beta found.
Without going into specific cites, earlier research, well-established in the literature, define a musical “word” in a variety of ways: as a single pitch, intervals (same as our pitch differential), n-grams of notes (similar to our tuple of pitch differential and duration ratio, but generalized to any number of notes in a row), rhythmic values (duration, and pitch-duration pairs, as we are experimenting with in this post. The upshot is that pretty much all of these representations, diverse as they are, produce Zipf-like distributions, which in turn implies a Heaps-like vocabulary growth similar to human languages.
Enough of the literature review. Here are the results of our Heaps’ Law analysis of the Skiptune database of 5 million notes where a musical “word” is defined as a pitch-duration tuple:
- 4.8 million “words” total (includes duplicates)
- 3,940 distinct pitch-duration tokens
- Explains about 97 percent of the variation in the notes
- Beta = 0.3185
Note the striking finding: The Beta for the Skiptune database of melodies is 0.32, whereas the beta for the study on classical works was 0.35, the beta for the Korean court music study was 0.36. By any measure, this is a remarkable confirmation that “musical language” features Heaps-like vocabulary growth, but with unusually strong compression and reuse relative to spoken language. That is the central result.
The implication is that vocabulary does not saturate. New pitch-duration combinations continue appearing throughout the corpus, but the discovery rate is very slow (hence the low betas) and novelty decays rapidly as the corpus grows.
Musically, this means that composers overwhelmingly reuse existing pitch-duration primitives, and that the effective local melodic grammar is highly constrained (they tend to follow the tried and true in general). It also means the space of acceptable pitch-duration events is small compared to language vocabularies.
Nearly 4.9 million observed tokens but fewer than 4,000 unique types suggests extraordinary compression. For comparison, a 5 million-word English corpus would typically contain hundreds of thousands of unique words.
Music here behaves much more like a tightly constrained symbolic grammar than an open lexical system (language).
Let’s look at this visually.
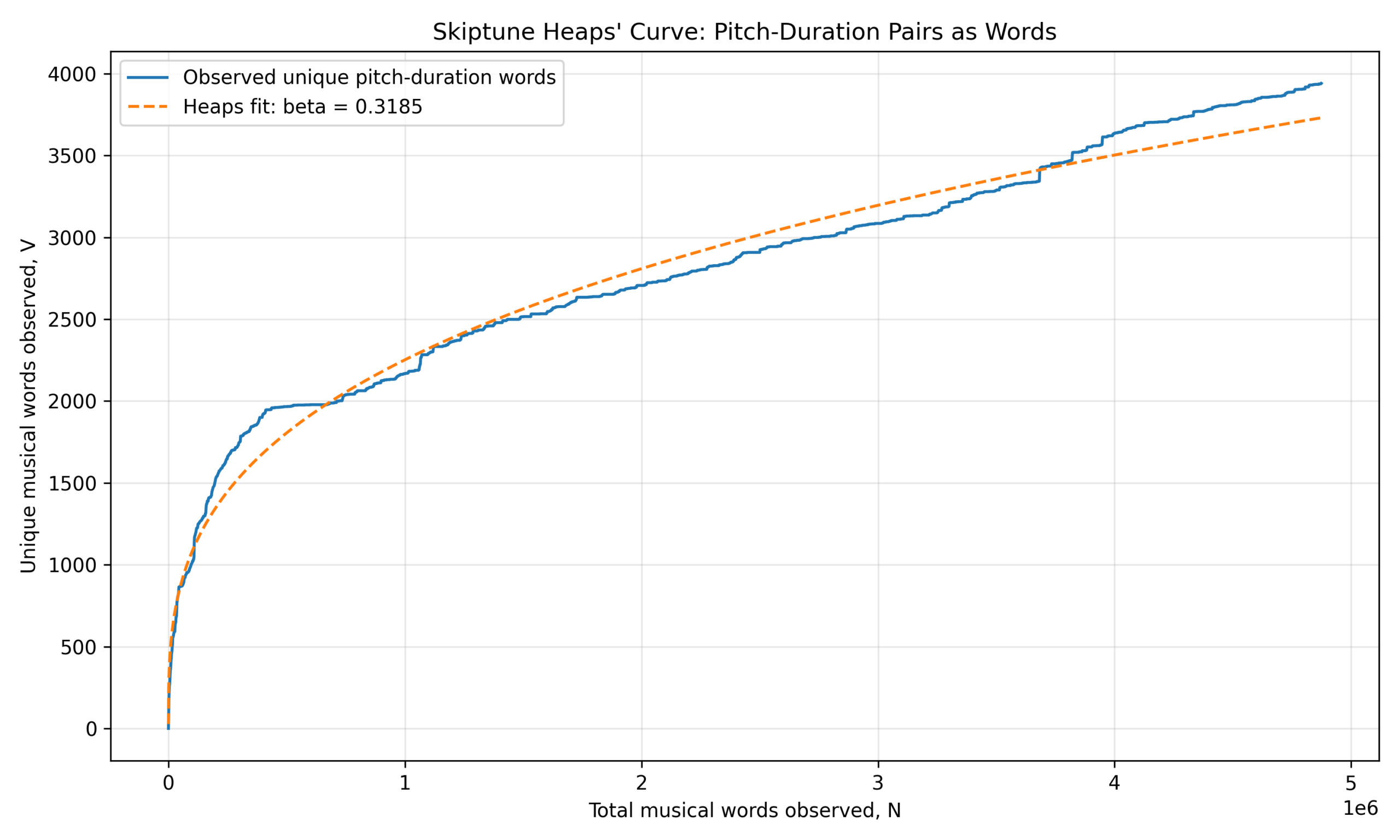
The figure is a straightforward, linear plot of the Heaps’ Curve from the corpus along with the best Heaps’ Curve fit. The horizontal axis is the count of total musical “words” (pitch-duration tuples) encountered in the corpus in millions. The vertical axis is the count of unique musical “words” encountered. The blue line represents the data plotted from the corpus, and the red line is the Heaps’ Curve fitted to the data.
The first thing to notice is that the fit is not quite as smooth as those in last week’s post. The blue curve juts up explosively, beyond the red curve fit, but eventually rejoins it, then underestimates, and toward the end it crosses the line to overestimate relative to the fit.
The fact that the blue curve juts up so quickly suggests that many basic pitch-duration combinations are discovered almost immediately. This means: that the “core musical lexicon” is small and heavily reused. The corpus contains common pitches, common note lengths, and standard tonal-rhythmic building blocks very early. As a result, the curve quickly reaches 2000 unique types (on the vertical axis) relatively early before slowing dramatically.
This is evidence that music has a dense, high-frequency kernel vocabulary.
The curve visibly flattens between roughly 400,000 and 700,000 tokens, suggesting that the corpus spends very long stretches recycling already-known pitch-duration units. That is probably caused by common melodic figures and repeated rhythms, possibly because we inadvertently entered a long stretch of tunes from the same era. It also may suggest stylistic standardization and historical reuse of melodic patterns.
This is where music diverges most strongly from language. Human language constantly creates new proper nouns, inflections, compound words, and completely new words. Pitch-duration vocabularies do not have equivalent productivity.
The late-stage upward bending near the far right side of the plots, especially after 3.5 million tokens, shows the observed curve rises above the fitted power law. This is interesting because it suggests that new vocabulary is appearing faster than the simple global power-law fit predicts, arguably because historical or style diversification in the later portions of the corpus. It may because we started adding more recently composed melodies toward the end of the data entering period.
Possible causes for the sudden new vocabulary are post-Romantic chromaticism, ragtime (and then jazz) syncopation, and modern rhythmic diversity in the middle of the 1900s (including rock). This upward deviation strongly argues against true saturation. We still appear to be discovering new local musical primitives at nontrivial rates. This observation aligns with the fact that we’re still encountering about 4 new tuples per 1,000 melodies.
Next week we’ll continue to explore how well the pitch-duration “word” in music would work in an AI model whose architecture is similar to that of a large language model.